
 Explore
Explore Write
Write Chat
Chat Call
Call
High Performance & Scientific Computing
Lustre User Guide on ISAAC ORI
Service navigation
The Lustre file system on the cluster exists across a set of 42 block storage devices called Object Storage Targets (OSTs). The OSTs are managed by Object Storage Servers (OSSs). Each file in a Lustre file system is broken into chunks and stored on a subset of the OSTs. A single service node serving as the Metadata Server (MDS) assigns and tracks all of the the storage locations associated with each file in order to direct file I/O (input/output) requests to the correct set of OSTs and corresponding OSSs. The metadata itself is stored on a block storage device referred to as the MDT.
Lustre Components
The Lustre file system is made up of an underlying set of I/O servers called Object Storage Servers (OSSs) and disks called Object Storage Targets (OSTs). The file metadata is controlled by a Metadata Server (MDS) and stored on a Metadata Target (MDT). A single Lustre file system consists of one MDS and one MDT. The functions of each of these components are described in the following list.
- Object Storage Servers (OSSs) manage a small set of OSTs by controlling I/O access and handling network requests to them. OSSs contain some metadata about the files stored on their OSTs. They typically serve between 2 and 8 OSTs, up to 16 TB in size each.
- Object Storage Targets (OSTs) are block storage devices that store user file data. An OST may be thought of as a virtual disk, though it often consists of several physical disks, in a RAID configuration for instance. User file data is stored in one or more objects, with each object stored on a separate OST. The number of objects per file is user configurable and can be tuned to optimize performance for a given workload.
- The Metadata Server (MDS) is a single service node that assigns and tracks all of the storage locations associated with each file in order to direct file I/O requests to the correct set of OSTs and corresponding OSSs. Once a file is opened, the MDS is not involved with I/O to the file. This is different from many block-based clustered file systems where the MDS controls block allocation, eliminating it as a source of contention for file I/O.
- The Metadata Target (MDT) stores metadata (such as filenames, directories, permissions and file layout) on storage attached to an MDS. Storing the metadata on a MDT provides an efficient division of labor between computing and storage resources. Each file on the MDT contains the layout of the associated data file, including the OST number and object identifier and points to one or more objects associated with the data file.
Figure 1.1 shows the interaction among Lustre components in a basic cluster. The route for data movement from application process memory to disk is shown by arrows.
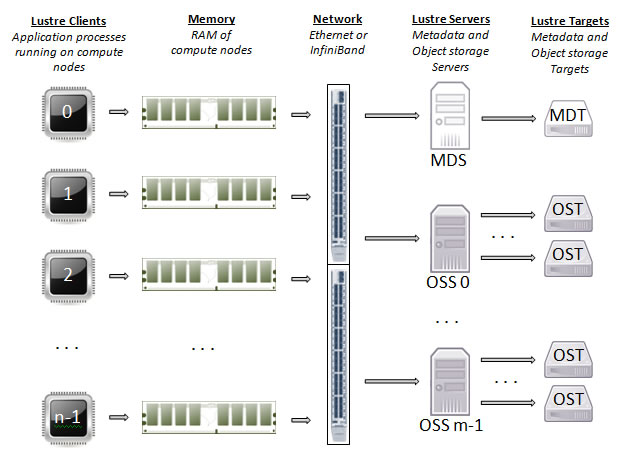
When a compute node needs to create or access a file, it requests the associated storage locations from the MDS and the associated MDT. I/O operations then occur directly with the OSSs and OSTs associated with the file bypassing the MDS. For read operations, file data flows from the OSTs to memory. Each OST and MDT maps to a distinct subset of the RAID devices. The total storage capacity of a Lustre file system is the sum of the capacities provided by the OSTs.
File Striping Basics
A key feature of the Lustre file system is its ability to distribute the segments of a single file across multiple OSTs using a technique called file striping. A file is said to be striped when its linear sequence of bytes is separated into small chunks, or stripes, so that read and write operations can access multiple OSTs concurrently.
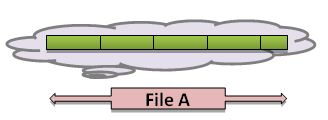
A file is a linear sequence of bytes lined up one after another. Figure 1.2 shows a logical view of a single file, File A, broken into five segments and lined up in sequence.
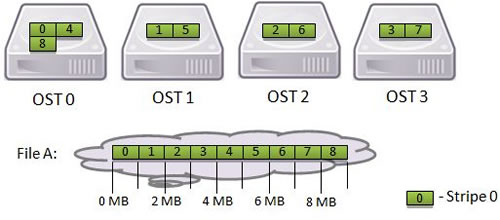
A physical view of File A striped across four OSTs in five distinct pieces is shown in Figure 1.3.

Storing a single file across multiple OSTs (referred to as striping) offers two benefits: 1) an increase in the bandwidth available when accessing the file and 2) an increase in the available disk space for storing the file. However, striping is not without disadvantages, namely: 1) increased overhead due to network operations and server contention and 2) increased risk of file damage due to hardware malfunction. Given the tradeoffs involved, the Lustre file system allows users to specify the striping policy for each file or directory of files using the lfs utility. The lfs utility usage can be found in the Basic Lustre User Commands section.
Stripe Alignment
Performance concerns related to file striping include resource contention on the block device (OST) and request contention on the OSS associated with the OST. This contention is minimized when processes (who access the file in parallel) access file locations that reside on different stripes.
Additionally, performance can be improved by minimizing the number of OSTs in which a process must communicate. An effective strategy to accomplish this is to stripe align your I/O requests. Ensure that processes access the file at offsets which correspond to stripe boundaries. Stripe settings should take into account the I/O pattern utilized to access the file.
Aligned Stripes
In Figure 1.3 we gave an example of a single file spread across four OSTs in five distinct pieces. Now, we add information to that example to show how the stripes are aligned in the logical view of File A. Since the file is spread across 4 OSTs the stripe count is 4. If File A has 9 MB of data and the stripe size is set to 1 MB it can be segmented into 9 equally sized stripes that will be accessed concurrently. The physical and logical views of File A are shown in Figure 1.4.
In this example, the I/O requests are stripe aligned, meaning that the processes access the file at offsets that correspond to stripe boundaries.
Non-Aligned Stripes
Next, we give an example where the stripes are not aligned. Four processes write different amounts of data to a single shared File B that is 5 MB in size. The file is striped across 4 OSTs and the stripe size is 1 MB, meaning that the file will require 5 stripes. Each process writes its data as a single contiguous region in File B. No overlaps or gaps between these regions should be present; otherwise the data in the file would be corrupted. The sizes of the four writes and their corresponding offsets are depicted in Figure 1.5.
- Process 0 writes 0.6 MB starting at offset 0 MB
- Process 1 writes 1.8 MB starting at offset 0.6 MB
- Process 2 writes 1.2 MB starting at offset 2.4 MB
- Process 3 writes 1.4 MB starting at offset 3.6 MB
The logical and physical views of File B are shown in Figure 1.5.
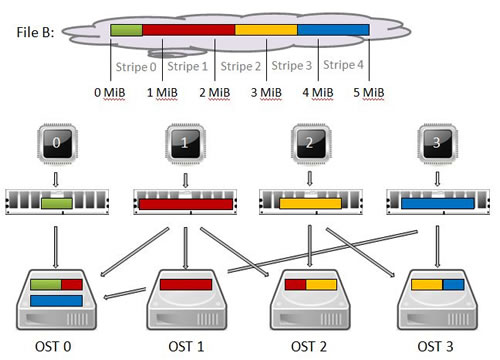
None of the four writes fit the stripe size exactly so Lustre will split each of them into pieces. Since these writes cross an object boundary, they are not stripe aligned as in our previous example. When they are not stripe aligned, some of the OSTs are simultaneously receiving data from more than one process. In our non-aligned example, OST 0 is simultaneously receiving data from processes 0, 1 and 3; OST 2 is simultaneously receiving data from processes 1 and 2; and OST 3 is simultaneously receiving data from processes 2 and 3. This creates resource contention on the OST and request contention on the OSS associated with the OST. This contention is a significant performance concern related to striping. It is minimized when processes (that access the file in parallel) access file locations that reside on different stripes as in our stripe aligned example.
I/O Benchmarks
The purpose of this section is to convey tips for getting better performance with your I/O on the cluster’s Lustre file system. You can also view our list of I/O Best Practices.
Serial I/O
Serial I/O includes those application I/O patterns in which one process performs I/O operations to one or more files. In general, serial I/O is not scalable.
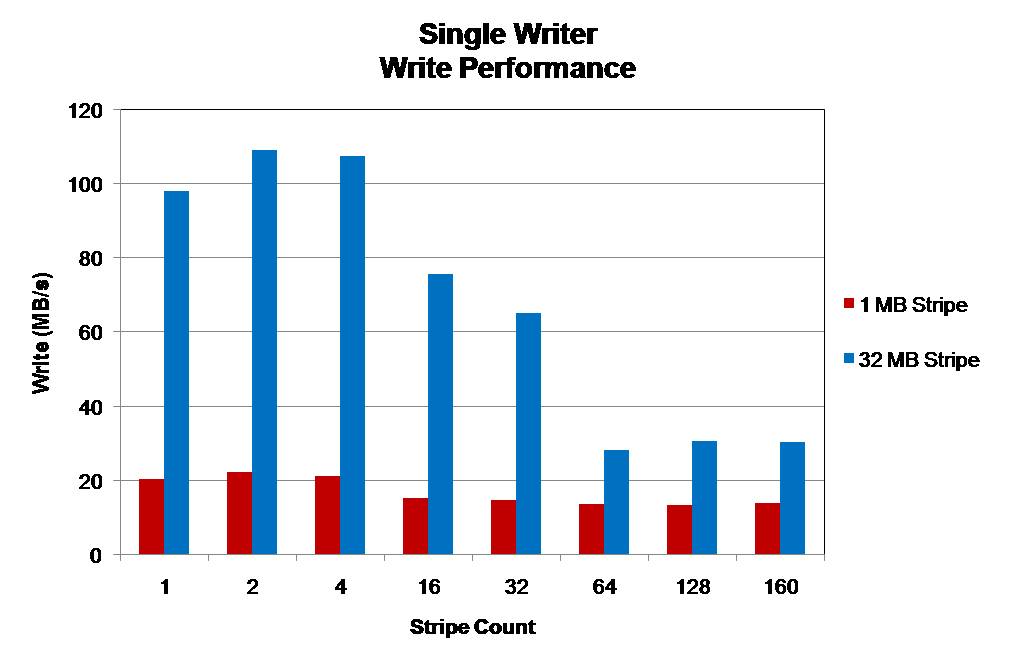
The file size is 32 MB per OST utilized and write operations are 32 MB in size. Utilizing more OSTs does not increase write performance. The best performance is seen by utilizing a stripe size which matches the size of write operations.
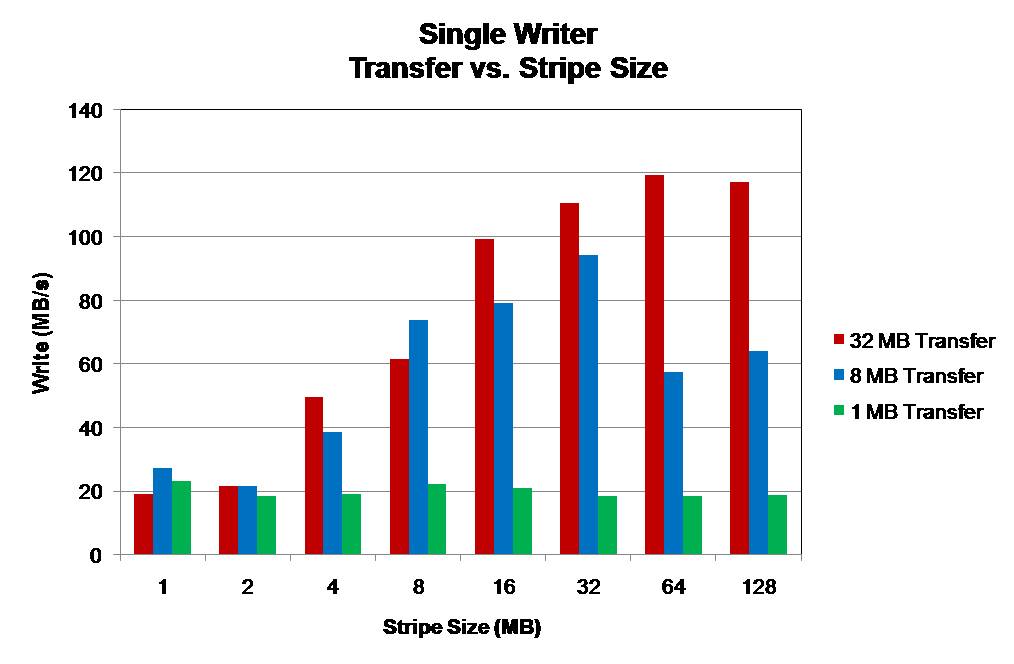
The utilized file is 256 MB written to a single OST. Performance is limited by small operation sizes and small stripe sizes. Either can become a limiting factor in write performance. The best performance is obtained in each case when the I/O operation and stripe sizes are similar.
- Serial I/O is limited by the single process which performs I/O. I/O operations can only occur as quickly as the single processes can read/write data to disk.
- Parallelism in the Lustre file system cannot be exploited to increase I/O performance.
- Larger I/O operations and matching Lustre stripe settings may improve performance. This reduces the latency of I/O operations.
File-per-Process
File-per-process is a communication pattern in which each process of a parallel application writes its data to a private file. This pattern creates N or more files for an application run of N processes. The performance of each process’s file write is governed by the statements made above for serial I/O. However, this pattern constitutes the simplest implementation of parallel I/O due to the possibility of improved I/O performance from a parallel file system.
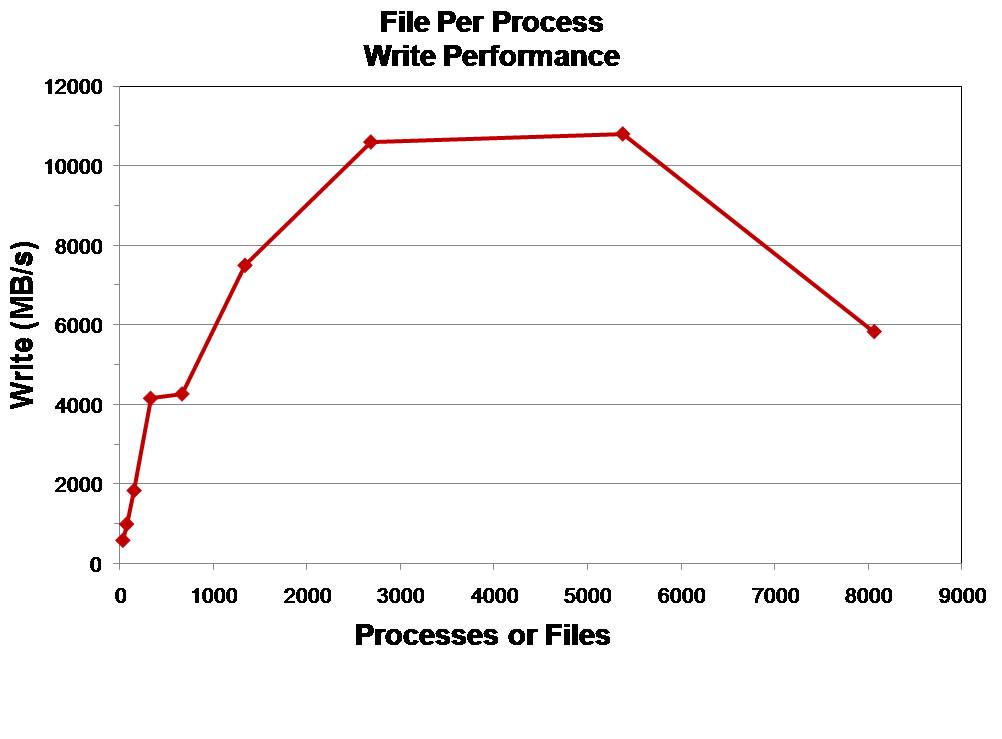
The file size is 128 MB with 32 MB sized write operations. Performance increases as the number of processes/files increases until OST and metadata contention hinder performance improvements.
- Each file is subject to the limitations of serial I/O.
- Improved performance can be obtained from a parallel file system such as Lustre. However, at large process counts (large number of files) metadata operations may hinder overall performance. Additionally, at large process counts (large number of files) OSS and OST contention will hinder overall performance.
Single-shared-file
A single shared file I/O pattern involves multiple application processes which either independently or concurrently share access to the same file. This particular I/O pattern can take advantage of both process and file system parallelism to achieve high levels of performance. However, at large process counts contention for file system resources OSTs can hinder performance gains.
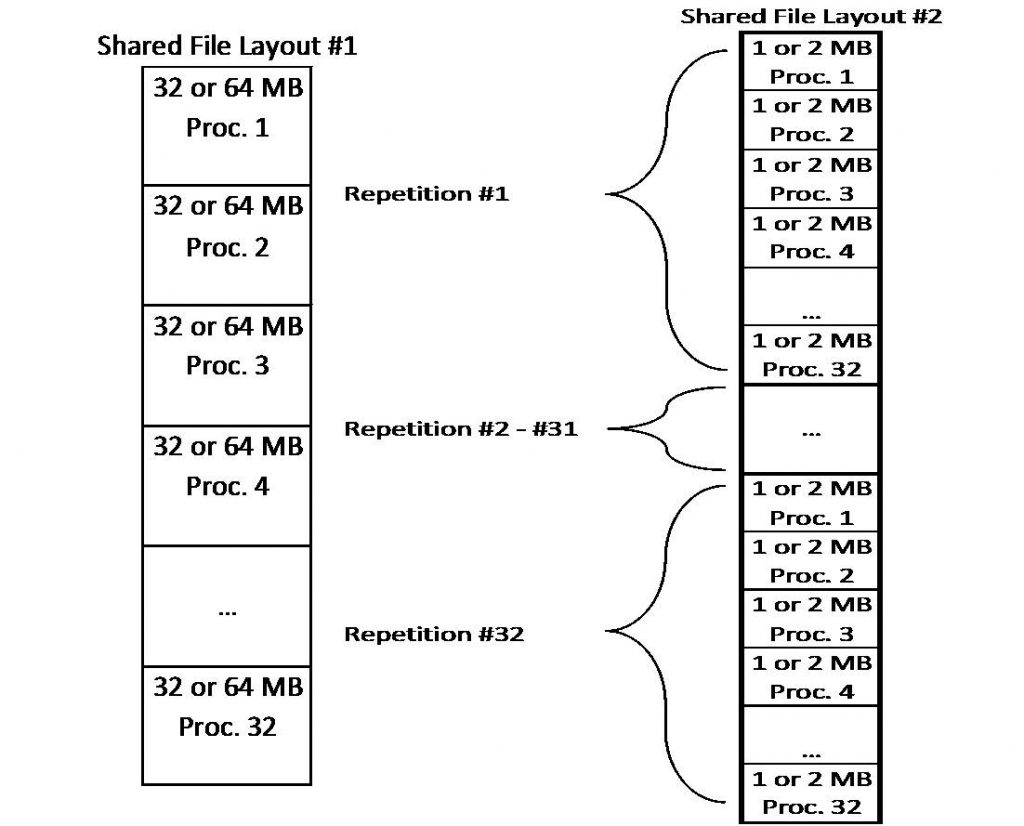
The aggregate file size in both cases is 1 and 2 GB depending on which block size is utilized. The major difference in file layouts is the locality of the data from each process. Layout #1 keeps data from a process in a contiguous block, while Layout #2 stripes this data throughout the file. Thirty-two (32) processes will concurrently access this shared file.
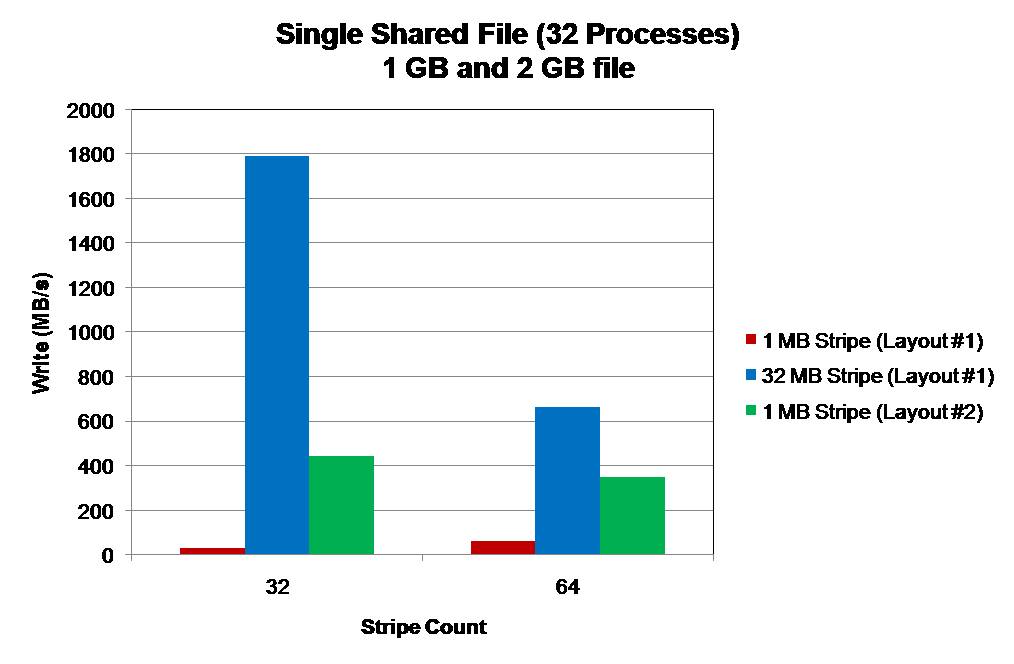
Stripe counts utilized are 32 (1 GB file) and 64 (2 GB file) with stripe sizes of 32 MB and 1 MB. A 1 MB stripe size on Layout #1 results in the lowest performance due to OST contention. Each OST is accessed by every process. The highest performance is seen from a 32 MB stripe size on Layout #1. Each OST is accessed by only one process. A 1 MB stripe size gives better performance with Layout #2. Each OST is accessed by only one process. However, the overall performance is lower due to the increased latency in the write (smaller I/O operations). With a stripe count of 64 each process communicates with 2 OSTs.
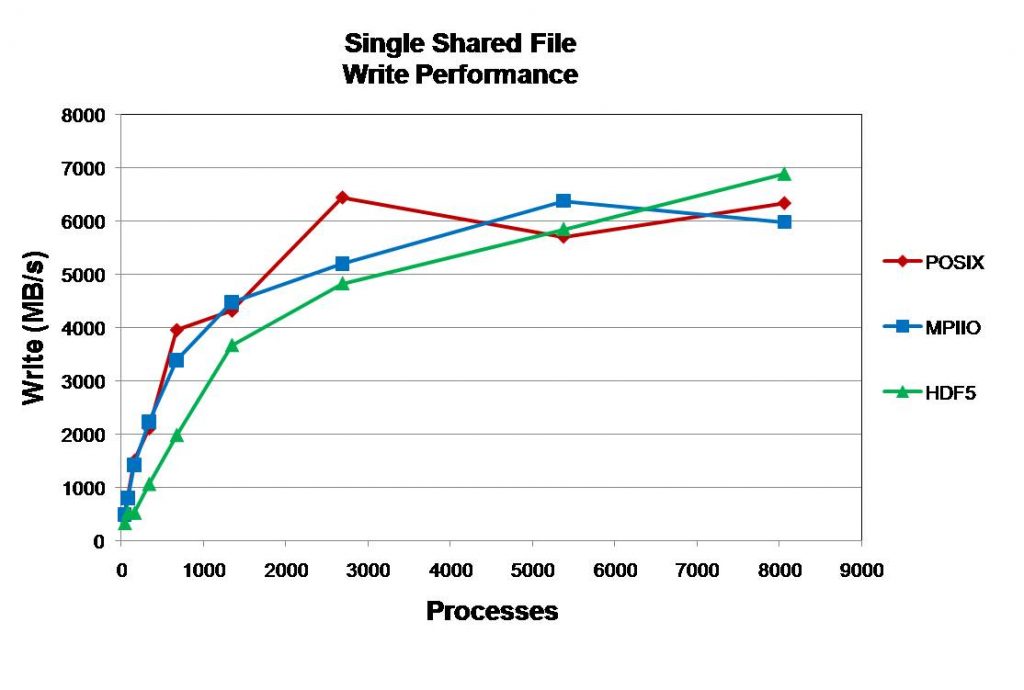
A file size of 32 MB per process is utilized with 32 MB write operations. For each I/O library (Posix, MPI-IO, and HDF5) performance levels off at high core counts.
- The layout of the single shared file and its interaction with Lustre settings is particularly important with respect to performance.
- At large core counts file system contention limits the performance gains of utilizing a single shared file. The major limitation is the 160 OST limit on the striping of a single file.
Basic Lustre User Commands
Lustre’s lfs utility provides several options for monitoring and configuring your Lustre environment. In this section, we describe the basic options that enable you to:
- List OSTs in the File System
- Search the Directory Tree
- Check Disk Space Usage
- Get Striping Information
- Set Striping Patterns
For a complete list of available options, type help at the lfs prompt.
$ lfs help
To get more information on a specific option, type help along with the option name.
$ lfs help option-name
You may also execute man lfs to review a list of the utility’s options.
Search the Directory Tree
Search the Directory Tree
The lfs find command searches the directory tree rooted at the given directory / filename for files that match the specified parameters. To review a list of all the options you may use with lfs find, execute lfs find help or man lfs.
Note that it is usually more efficient to use lfs find rather than use GNU find when searching for files on Lustre.
Some of the most commonly used lfs find options are described in Table 3.1. For more options, please review the man page for the lfs utility.
| Parameter | Description |
|---|---|
| –atime | File was last accessed N*24 hours ago. (There is no guarantee that atime is kept coherent across the cluster.) |
| –mtime | File status was last modified N*24 hours ago. |
| –ctime | File status was last changed N*24 hours ago. |
| –maxdepth | Limits find to descend at most N levels of the directory tree. |
| –print / –print0 | Prints the full filename, followed by a new line or NULL character correspondingly. |
| –size | File has a size in bytes or kilo-, Mega-, Giga-, Tera-, Peta- or Exabytes if a suffix is given. |
| –type | File has the type (block, character, directory, pipe, file, symlink, socket or Door [Solaris]). |
| –gid | File has a specific group ID. |
| –group | File belongs to a specific group (numeric group ID allowed). |
| –uid | File has a specific numeric user ID. |
| –user | File is owned by a specific user (numeric user ID is allowed). |
Using an exclamation point “!” before an option negates its meaning (files NOT matching the parameter). Using a plus sign “+” before a numeric value means files with the parameter OR MORE. Using a minus sign “-” before a numeric value means files with the parameter OR LESS.
Consider an example of a 3-level directory tree shown in Figure 3.3.

Results from using the lfs find command with various parameters are given in Table 3.2.
| Command | Result |
|---|---|
| lfs find /ROOTDIR | /ROOTDIR /ROOTDIR/level_1_file /ROOTDIR/LEVEL_1_DIR /ROOTDIR/LEVEL_1_DIR/level_2_file /ROOTDIR/LEVEL_1_DIR/LEVEL_2_DIR /ROOTDIR/LEVEL_1_DIR/LEVEL_2_DIR/level_3_file |
| lfs find /ROOTDIR –maxdepth 1 or lfs find /ROOTDIR –maxdepth 1 –print | /ROOTDIR /ROOTDIR/level_1_file /ROOTDIR/LEVEL_1_DIR |
| lfs find /ROOTDIR –maxdepth 1 –print0 | /ROOTDIR/ROOTDIR/level_1_file/ROOTDIR/LEVEL_1_DIR |
The example in Figure 3.4 uses the -mtime parameter to provide a recursive list of all regular files in the user’s Lustre scratch directory that are more than 30 days old.
$ lfs find $SCRATCHDIR -mtime +30 -type f -print
Figure 3.4 – lfs find Used to Identify Files More than 30 Days Old
I/O Best Practices
Lustre is a shared resource by all users on the system. Optimizing your IO performance will not only lessen the load on Lustre, but it will save you compute time as well. Here are some pointers to improve your code’s performance.
Working with large files on Lustre
Lustre determines the striping configuration for a file at the time it is created. Although users can specify striping parameters, it is common to rely on the system default values. In many cases, the default striping parameters are reasonable, and users do not think about the striping of their files. However, when creating large files, proper striping becomes very important.
The default stripe count on the cluster’s Lustre file system are not suitable for very large files. Creating large files with low stripe counts can cause IO performance bottlenecks. It can also cause one or more OSTs (Object Storage Targets, or “disks”) to fill up, resulting in I/O errors when writing data to those OSTs.
When dealing with large Lustre files, it is a good practice to create a special directory with a large stripe count to contain those files. Files transferred to (e.g., scp/cp/gridftp) or created in (e.g., tar) this larger striped directory will inherit the stripe count of the directory. Figure 4.1 shows how to create a large striped directory on the cluster.
[user-x@acf-login6 ~]$ cd $SCRATCHDIR [user-x@acf-login6 user-x]$ mkdir large_files [user-x@acf-login6 user-x]$ lfs setstripe -c 30 large_files/ [user-x@acf-login6 user-x]$ lfs getstripe -d large_files/ large_files/ stripe_count: 30 stripe_size: 1048576 stripe_offset: -1
Figure 4.1 – Creating a Large Stripe Directory
In the above example, the default stripe count for the directory is set to 30. For directories, the stripe count should be set to the expected size of the files in the directory. For files, one stripe per 100GB of data is sufficient. For instance, a 3TB file could use a stripe count of 30. For much larger files, a stripe count of -1 is preferred so that the files are striped across all the OSTs.
Examples
A tar archive can be created and placed within the directory with a large stripe size. The archive will inherit the stripe size of the directory. Figure 4.2 shows how to use the tar command to create the archive and place it within the appropriate directory.
[user-x@acf-login6 ~]$ cd $SCRATCHDIR [user-x@acf-login6 user-x]$ tar cf large_files/sim_data.tar sim_data/ [user-x@acf-login6 user-x]$ ls -l large_files/ total 1 -rw-r--r--. 1 user-x user-x 10240 May 8 10:48 sim_data.tar
Figure 4.2 – Creating a tar Archive in the large_files Directory
This will tar up the sim_data directory and places it in the larger striped directory. Note, one can add the “j” flag for the bz2 compression (the file would change to sim_data.tar.bz2).
Conversely, if one has a large tar file in the LARGE_FILES directory, and this tar file contains many smaller files, it can be extracted to a separate directory with a smaller stripe count. Figure 4.3 demonstrates this process.
[user-x@acf-login6 user-x]$ mkdir small_stripe [user-x@acf-login6 user-x]$ lfs getstripe small_stripe/ small_stripe/ stripe_count: 2 stripe_size: 1048576 stripe_offset: -1 [user-x@acf-login6 user-x]$ tar xf large_files/sim_data.tar -C small_stripe/ [user-x@acf-login6 user-x]$ ls -l small_stripe/ total 4 drwxr-xr-x. 2 user-x user-x 4096 May 8 10:47 sim_data
Figure 4.3 – Extract a tar Archive to a Separate Directory with a Smaller Stripe Count
This will extract the tar file into a directory with a default stripe count of 2.