
 Explore
Explore Write
Write Chat
Chat Call
Call
High Performance & Scientific Computing
Web-browser-based Access with Open OnDemand
Service navigation
Introduction
OpenOnDemand is a web-based portal/interface that provides access to the cluster’s HPC resources. You can manage files, jobs, and access graphical interfaces all through OpenOnDemand. This document describes how to access and use OpenOnDemand and its related services.
Access and Login
Please follow the below steps to successfully log in to the web based graphical interface of ISAAC-NG cluster.
- Open a web browser and type
login.isaac.utk.eduorlogin.isaac.tennessee.eduin the address bar. This will take you to the University’s Central Authentication System (CAS) to validate your credentials as shown in Figure 4.1 below.
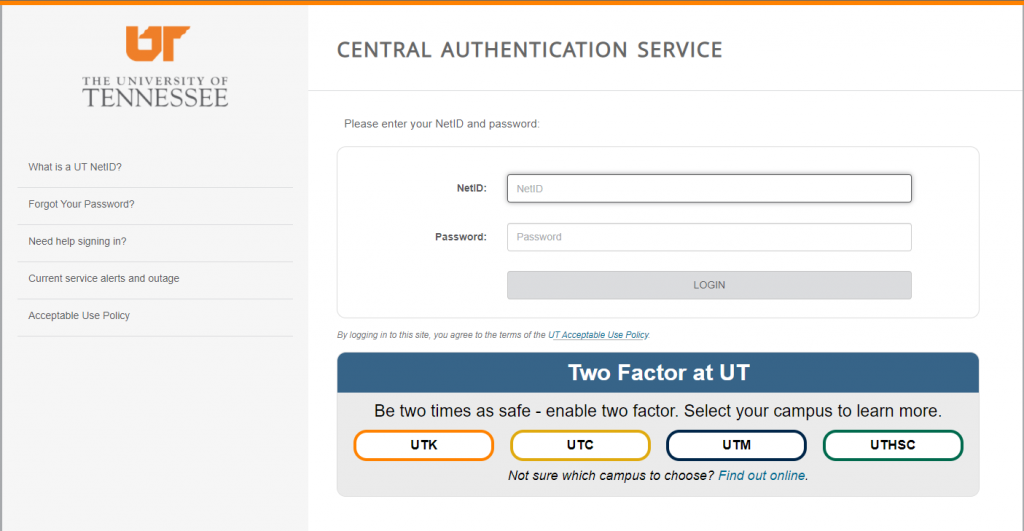
- Enter your UTNetID and password. Press Enter or click on the LOGIN button.
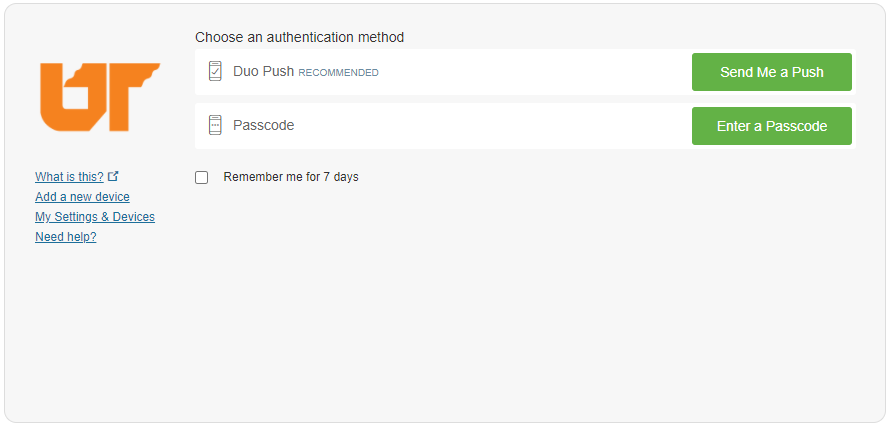
- After you successfully login, Duo TFA will come up. Select Duo Push or Passcode to log in. The authentication method will be sent to your mobile device. Figure 4.2 shows the Duo TFA options that will appear.
Upon successful authentication, you will see the Open OnDemand dashboard. The top-left of the dashboard contains several menus that grant access to files, jobs, and your current interactive sessions as shown in Figure 4.3.

File Explorer
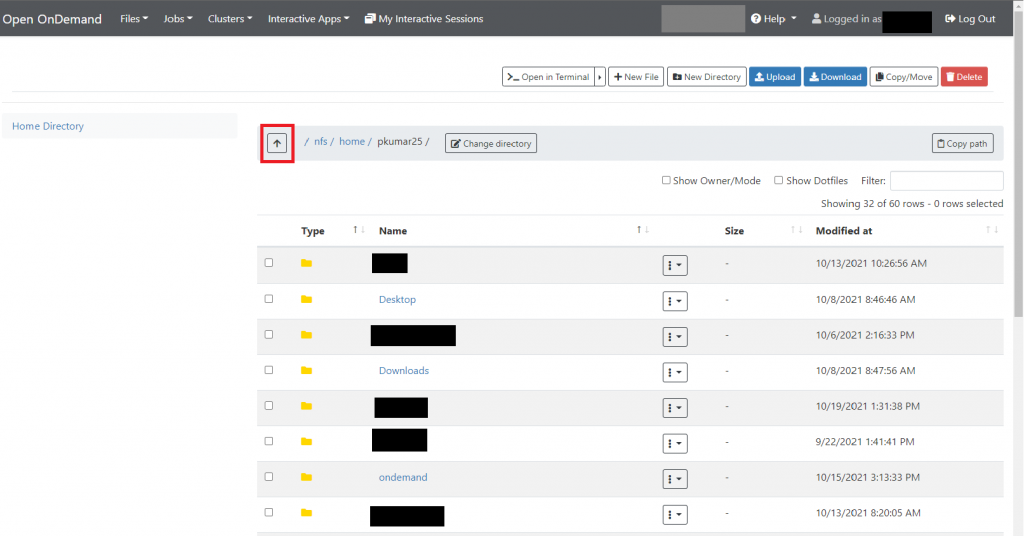
The “Files” menu in the top-left of the OpenOnDemand dashboard gives you access to your files on the ISAAC-NG cluster from within a browser. Initially, the File Explorer shows your home directory and all its contents. Figure 4.4 shows the File Explorer interface.
File Explorer Navigation
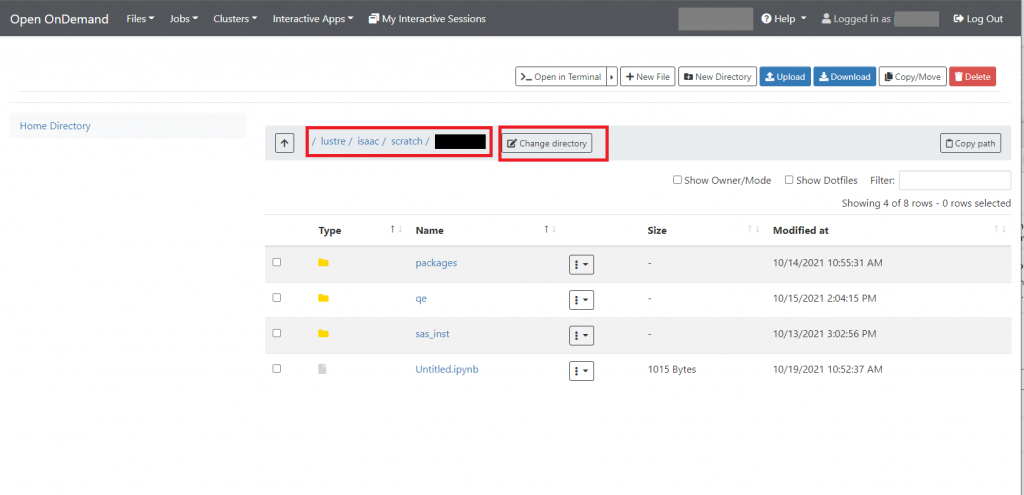
To navigate through directories, click on the directory you wish to enter. To return to your former directory, click on the up arrow highlighted with a red box. If unsure where you are located within the directory tree, look above the directory listing pane (near the red box marked in Figure 4.4). You will see several names and letters separated by forward slashes (/). This indicates the absolute pathname of your current location. In Figure 4.4, the current directory of the user is his/her home directory located at /nfs/home/<netID>.
In the left pane of the File Explorer, you see the button for your home directory. If at any time you wish to return to the top-level of your home directory, click on Home Directory. You may also navigate to directories within your home directory using the central pane.
To quickly navigate to a specific directory, click on the Change Directory button next to the absolute path as shown in Figure 4.4. A new window similar to the one below will appear.
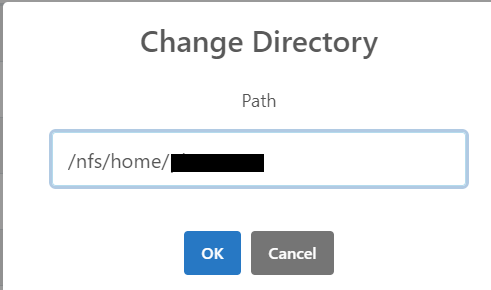
Enter the absolute path of the directory where you wish to change to go and click OK. For example, to navigate to your Lustre directory, type /lustre/isaac/scratch/<netID> where <netID> is your University NetID. The file explorer will then place you in the specified directory and display its contents as shown in Figure 4.6.
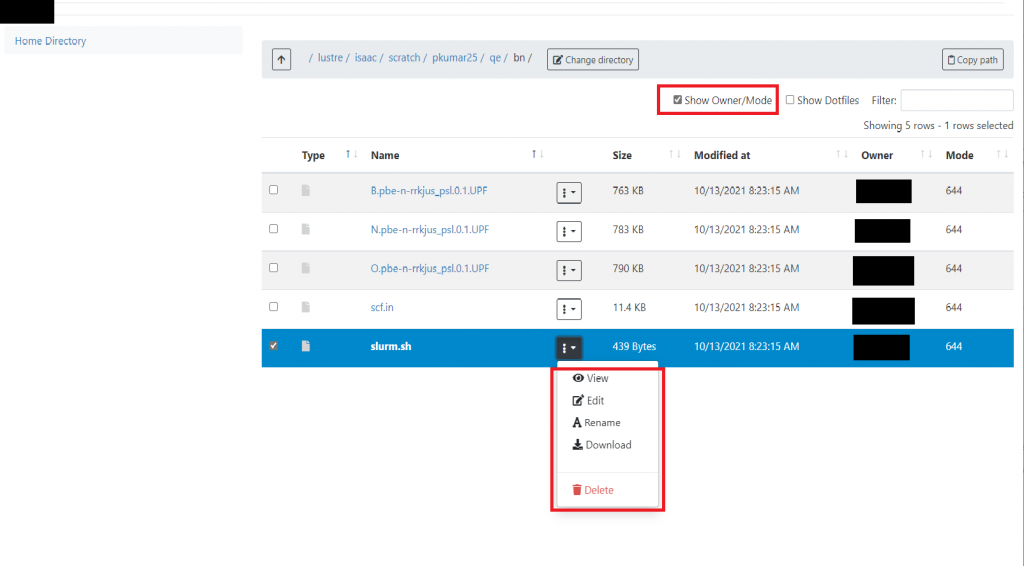
OpenOnDemand’s file explorer can show permissions, ownership, and hidden files. In the top-right of the central pane of the file explorer interface, check the boxes for “Show Dotfiles” and “Show Owner/Mode” to enable these views. Figure 4.7 shows the directory listing pane with the Show Owner/Mode option enabled. Permissions and ownership cannot be modified from within this interface. Hidden files are prefaced with a dot (.) and are usually user configuration files.
To view a specific file, select the file in the directory listing pane. Click on the file or the dropdown menu marked with red box as shown in Figure 4.7 and click View, the plaintext contents of the file will appear in a new window. To edit the file, select the Edit option from the drop down menu.
Creating, Modifying and Deleting Files
To create a new file in File Explorer, select the option labeled New File, as shown in Figure 4.6 on the top right just above the central pane. Its icon is a sheet of paper with a plus (+) symbol. When you click the option, File Explorer will prompt you to name the file. After you name the file and confirm its creation, it will be placed within your current directory.
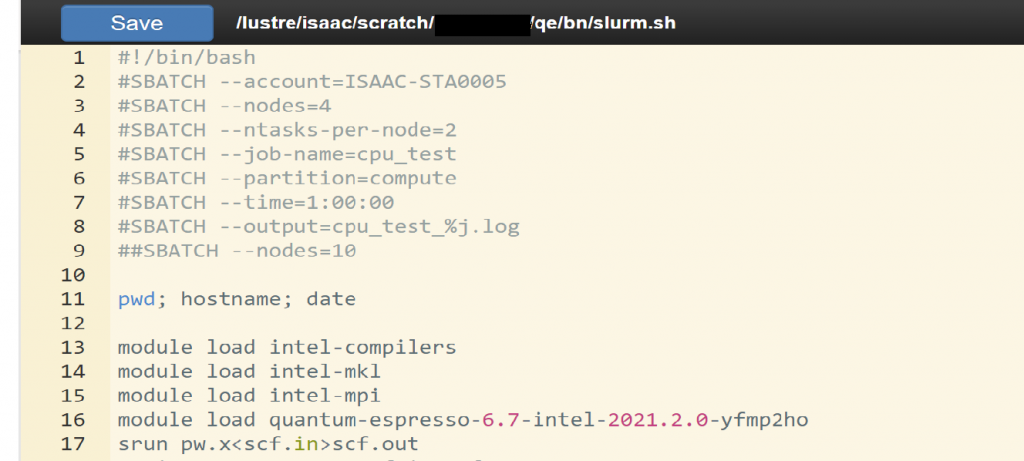
To modify the file, select the file in the directory listing pane, then select the option labeled Edit, as shown in Figure 4.7 Its icon is a canvas with a paintbrush on top of it. The OpenOnDemand editor will open. You can then type the information you wish to put in the file. The editor features several customization options, such as the editor’s theme and text mode. Figure 4.8 shows the OpenOnDemand file editor. When you finish editing the file, click “Save” in the top-left of the editor. When you return to the File Explorer and view the file, you can view the changes you made.
The File Explorer also allows you to rename existing files and directories. To rename a file or directory, select the item you wish to rename in the directory listing pane. From the dropdown menu marked with the red box in Figure 4.7, choose the option labeled “Rename.” The File Explorer will prompt you for the new name, and once you confirm it, your changes will take immediate effect.
Files and directories can be copied and pasted within File Explorer. To copy a file or directory, select the item in the directory listing pane, then select the option labeled Copy on the top right side. Once the item has been copied to your clipboard, navigate to the location where you intend to copy the file, then select the option labeled “Paste.” The copied item will then appear in your current directory.
If you wish to delete a file or directory, select the item in the directory listing pane, then select the Delete shown in the marked box in Figure 4.7. You will be prompted to confirm the deletion. Once confirmed, the item will be permanently deleted.
Downloading and Uploading Files
Files can be both downloaded from and uploaded to the cluster through File Explorer. Only small files should be transferred between the cluster and your local system through File Explorer. For larger file transfers, please use Globus. More information on how to configure and use Globus can be found in the Data Transfer document.
To download a file from the cluster to your local system, select the file in the directory listing pane. If you wish to download multiple files, hold down the Ctrl key on Windows and Linux systems or the Command key on MacOS, then select each file in the directory listing pane.
Once all the files you wish to download are selected, click the option labeled Download on the top right side of the File explorer. It is indicated with a down arrow. After the download completes, the file(s) will appear in your Downloads folder unless you have specified another location for downloads. Be aware that most browsers block attempts to download multiple files unless you explicitly allow the transfer.
To upload a file to the cluster from your local system, select the Upload option in the top-right of the File Explorer interface. The Explorer will prompt you to choose a file. Select Choose Files when the dialog box appears. You may select the file(s) you want to upload to the cluster from your local system. In addition to this method, you may drag and drop files from your local system into File Explorer. These items will then appear in the directory listing pane.
Job Management
Under the Jobs drop-down menu next to Files, you have two options: Active Jobs and Job Composer. Both options provide advanced job management from within a web browser.
Job Monitoring
In the Active Jobs section, you will see an organized list of your queued and running batch jobs on the cluster. Figure 4.9 shows the Active Jobs interface. You can filter through jobs to see particular entries, in addition to sorting by the attributes of your choice. To do this, click on the arrows next to the attributes until the list is sorted as you desire.
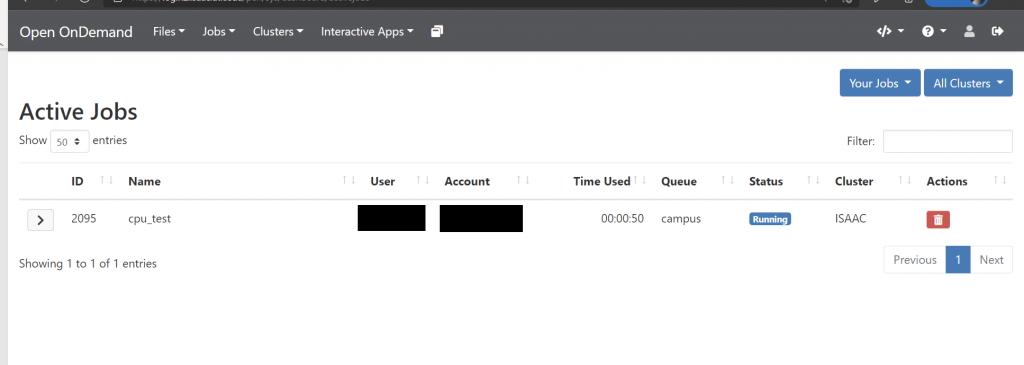
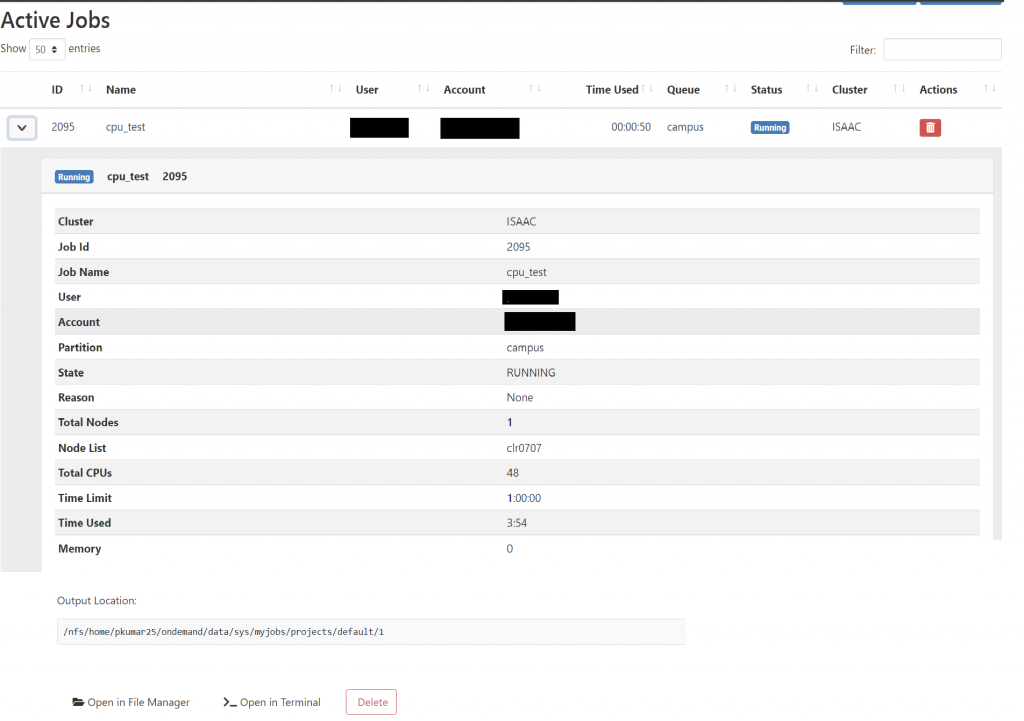
When a job is queued or running on the cluster, you can view detailed information on the job from within the Active Jobs interface. Figure 4.2 shows the information you will see on queued and running jobs.
To access this view on a queued or running job, click the right-facing arrow on the far-left of the job’s row. You will then see statistics and information about the selected job. Of note is the Output Location of the job, which Figure 4.10 highlights. Each job you create and start through OpenOnDemand is placed within your /home/ondemand directory, so when you wish to retrieve the job’s data, remember to navigate to your ondemand directory. You can specify another output location when you create the job through OpenOnDemand or edit the job script to supply another location.
Job Creation
In the Job Composer section, you can create new batch jobs to run on the cluster based upon several criteria. Figure 4.11 shows the Job Composer interface. When you initially open the Job Composer, the system will briefly explain each option available to you. Once you click through these prompts, you may then click “New Job,” then select the template, path, or job you wish to add. Note that if you close the initial information menu, you will not need to click through each prompt.
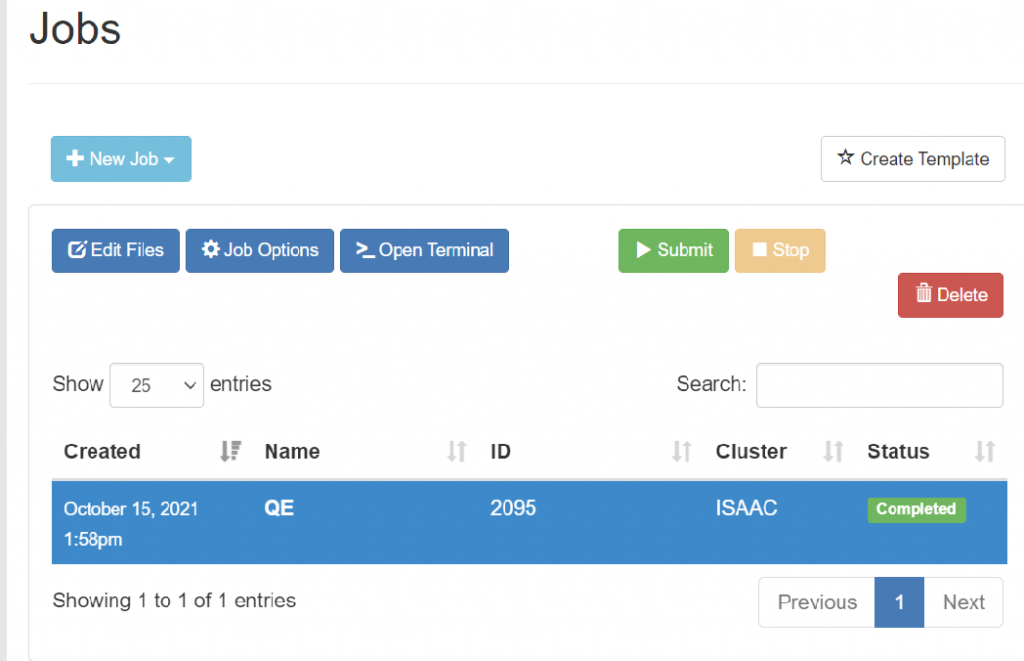
When you add a new job from the default template, the Job Composer will create a Simple Sequential Job. In addition to the job, it will create a job script and a job directory. Figure 4.11 shows the Job Composer interface when a job is created with the default template. To modify the job’s options, select Job Options. You can specify the job’s name, cluster, script, and account. To edit the job script, highlight the job and select the Edit Files option in the Job Composer interface. Select the job script, then select Edit. You may also rename the job script if necessary. Additional files can also be uploaded or created in the job’s directory from the File Explorer.
Jobs may also be created with other templates. These can be the default templates or templates that you build within the Job Composer and can be found under the dropdown menu +New Job as shown in Figure 4.11.
In addition to template-based job creation, you may also create jobs based upon a specified path or an existing job. With a specified path, you create a job based upon a directory that already exists. The path will either be to your home or project directory. Once you specify the path, you then modify the typical attributes of the job. With a job created based upon an existing one, select an existing job in the queue, navigate to New Job, then select “From Selected Job.”
Beyond job creation, the Job Composer allows you to submit, stop, and delete your existing jobs. Like the Active Jobs menu, you can filter and sort the available jobs.
ISAAC Desktop (noVNC)
noVNC allows users to interact with the cluster in a graphical desktop environment from within a web browser. noVNC is particularly useful when you require a graphical X11 application. Be aware that while most browsers support noVNC, outdated or uncommon browsers may not function. Please use Chrome, Firefox, Edge, or Safari when using noVNC interactive sessions.
To launch a noVNC session, log in to OpenOnDemand. In the dashboard, select “Interactive Apps” from the top-left of the window. In the dropdown menu, select “ISAAC Desktop.” This will open the session submission form depicted in Figures 4.12.
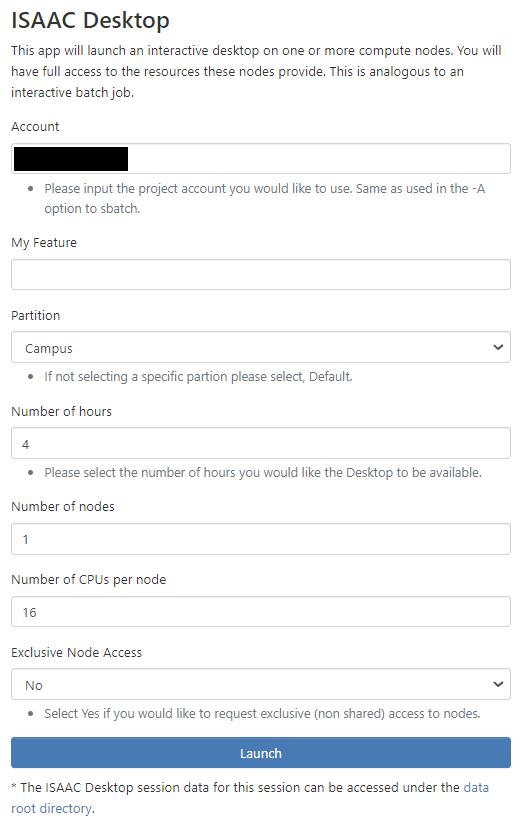
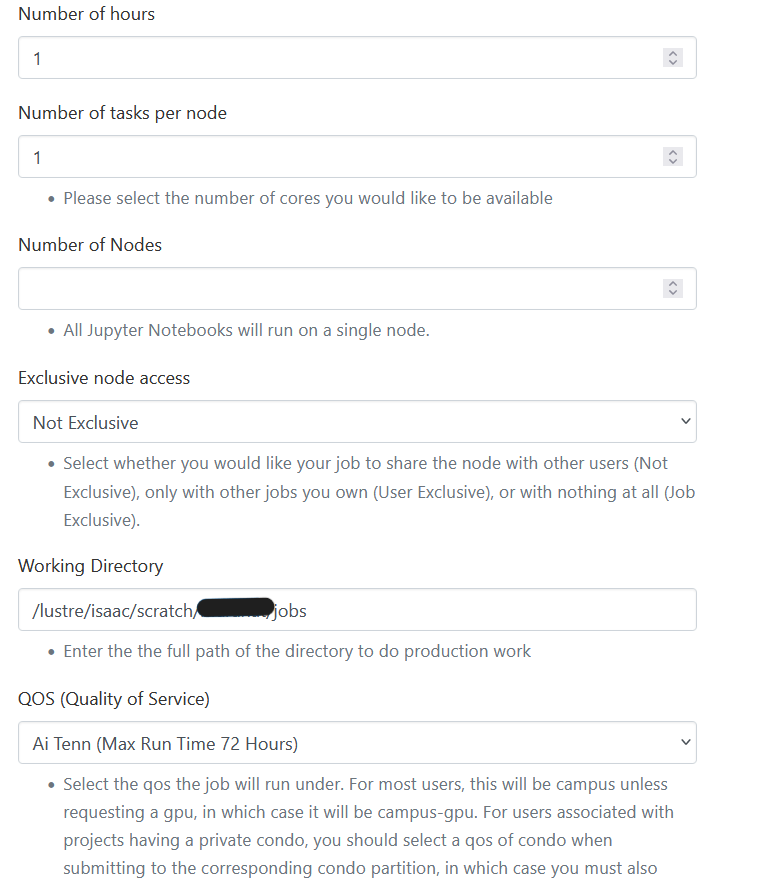
In this form, specify the resources your application(s) require. All the available options map to sbatch options for interactive jobs. To learn the meaning behind these options, please review the Interactive Jobs section of the Running Jobs document. For most situations, a single node with one core is sufficient. If your application requires GPUs, please specify campus-gpu as the partition. Leave the Features Requested entry set to “None” unless your job requires one of the specific options for CPU architecture. Please be aware that the number of cores per node you request directly influences the memory your job receives. Therefore, make sure to request enough cores for your job so that your job does not run out of memory leading to the termination of the job.
It is also important to note that you can request node-exclusivity for your session. With node-exclusivity, no other session will run on the node your session receives. In cases where the application you will use in the session is resource-intensive, setting this option to “Yes” may be beneficial. Otherwise, leave this option as “No.”
Submit the noVNC session to the scheduler by clicking on the Launch button in Figure 4.12. For most single-node, single-core jobs, the session should begin within five minutes; however, this is dependent on the current resource utilization of the cluster. If you requested multiple nodes or exclusive access to a node, it could take longer for the session to start. When the session is ready, access it by clicking the Launch ISAAC Desktop in New Tab button. Figure 4.13 highlights this button.
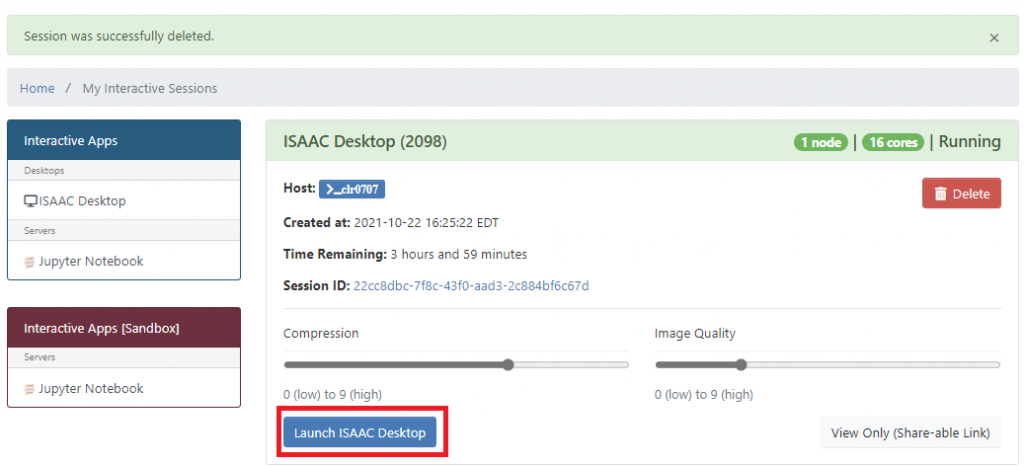
When you access the session, you will see a standard Linux XFCE desktop environment. In the top-left of the GUI, the Applications menu contains links to several useful packages. In the bottom-middle of the GUI, you can open your home directory with the file cabinet icon. The black icon with a greater-than (>) symbol in it opens a terminal. From this terminal you can perform any task you would from a standard terminal such as accessing files, loading modules, and running applications.
If you wish to manually terminate the noVNC session, click on your username in the top-right of the GUI and select “Log Out.” Then, delete the session in OpenOnDemand. You will receive an email confirmation of the job’s deletion.
Jupyter Notebook
Launching Jupyter Notebook
Jupyter Notebook is a web-based application that enables you to intuitively create and manipulate data on the cluster. It features a fully-functional Python 3 IDE (integrated development environment), a text editor, and a file manager. The sections below outline how to access and set up Jupyter Notebooks on the cluster.
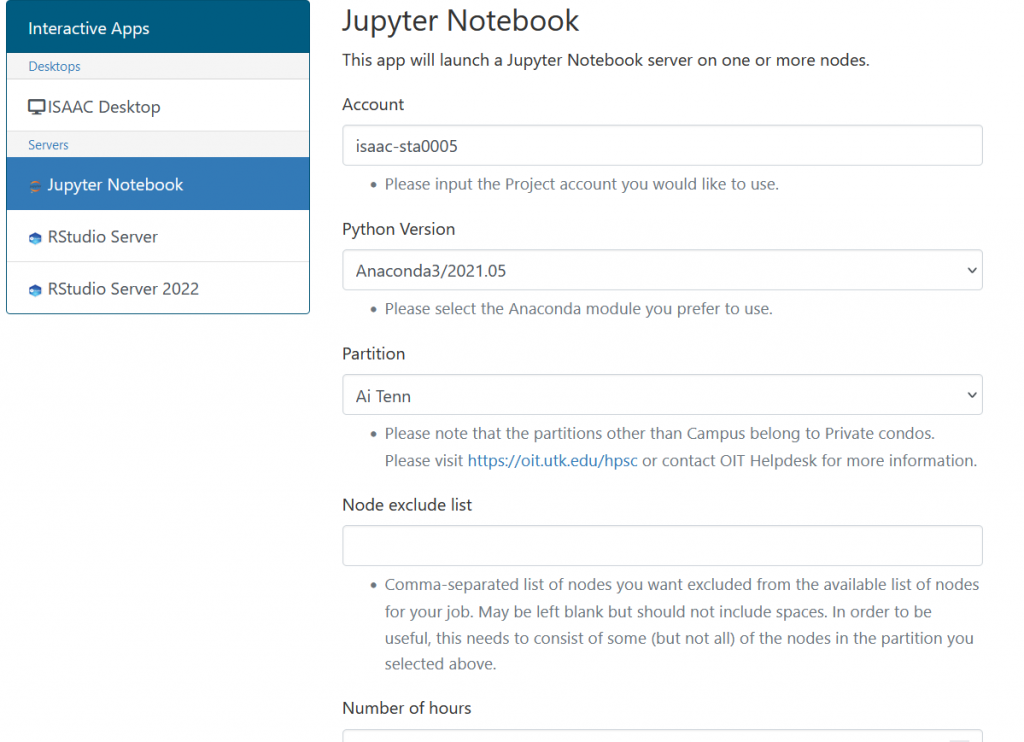
To access Jupyter Notebook, navigate to Interactive Apps on the OpenOnDemand dashboard. Select Jupyter Notebook from the dropdown menu. The Jupyter Notebook session submission form will appear as it does in Figure 4.14.
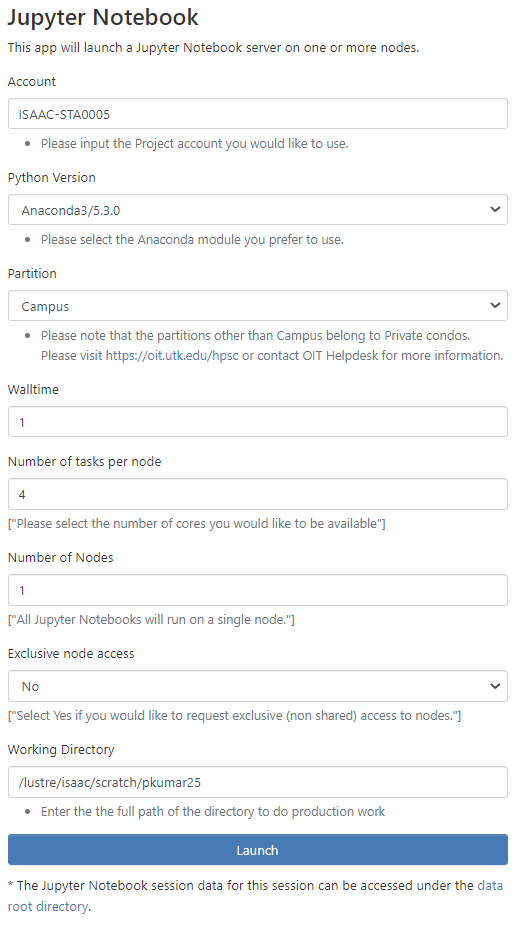
The Jupyter notebook in Open OnDemand is configured with Anacond3. We have provided two different versions of Anaconda. In this form, specify one of Anaconda’s versions to use the associated Jupyter Notebook, the account under which the job should run, the partition, the number of hours the job will run, and the number of cores your job requires. If you require GPUs in your Jupyter Notebook session, select the campus-GPU partition. Please review the Running Jobs document for more information on these fields.
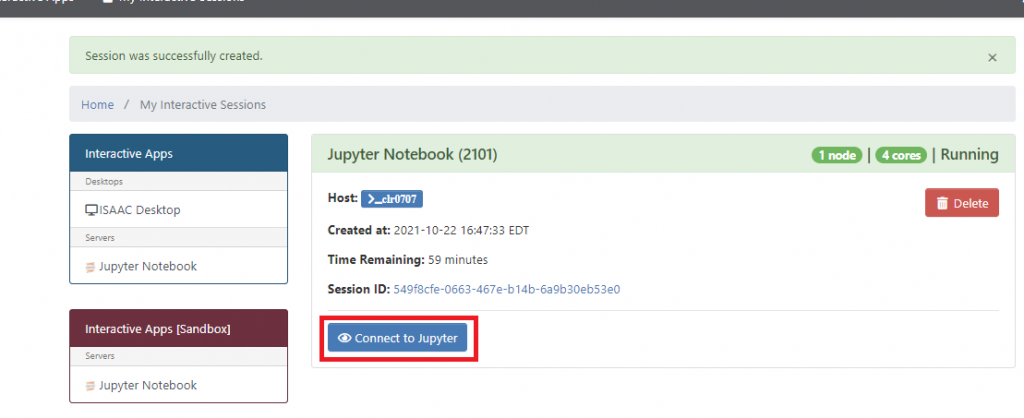
When you specify the necessary options in the form and select Launch. It will not take for the system long to deploy the Jupyter Notebook session, but this is dependent on the resources you requested. When the session is ready, you will see the similar interface that appears in Figure 4.13. The “Connect to” option will open a new Jupyter Notebook tab in your browser. Figure 4.15 highlights this option.
Open OnDemand (OOD) Examples
How to start a Jupyter Notebook session?
- From the top menu, choose “My Interactive Sessions.”
- Choose one of the interactive apps (ISAAC Desktop, Jupyter Notebook, RStudio Server, or RStudio Server 2022)
- The examples shown in this document use Jupyter Notebook.
How to check available resources?
Be aware that before you try to initiate a Jupyter Notebook job in OOD that you need to login to the ISAAC NG login node and check what compute node resources are available to run a Jupyter Notebook session. It is recommended to verify the availability of necessary resources before making a reservation to prevent prolonged waiting periods. If you don’t do this then you may make a request in the Jupyter Notebook form for resources that may take a long time to allocate for your work. In order to make the process go well and not take very long, you should investigate what resources are not in use and try to target those resources in the information you put in the Jupyter Notebook form.
From ISAAC NG command prompt, you can use ‘isaac-sinfo’ to identify any idle resources. The status is either “idle” meaning the entire compute node is available or “mixed” to indicate part of the node is available.
e.g.
$isaac-sinfo | egrep ‘idle|mixed’
,or
$isaac-sinfo | grep campus | grep -E ‘idle|mixed’
For more information, please visit the “Checking for Available Resources” section at Running Jobs on ISAAC-NG page.
Example 1 – Jupyter Notebook Simple Slurm job:
- The below example will show how to fill in the form to make a request for one node and one cpu.
- For this example, the default account “ACF-UTK0011” was used. The “Campus” partition and QOS was sufficient for running the simple_slurm_job example.
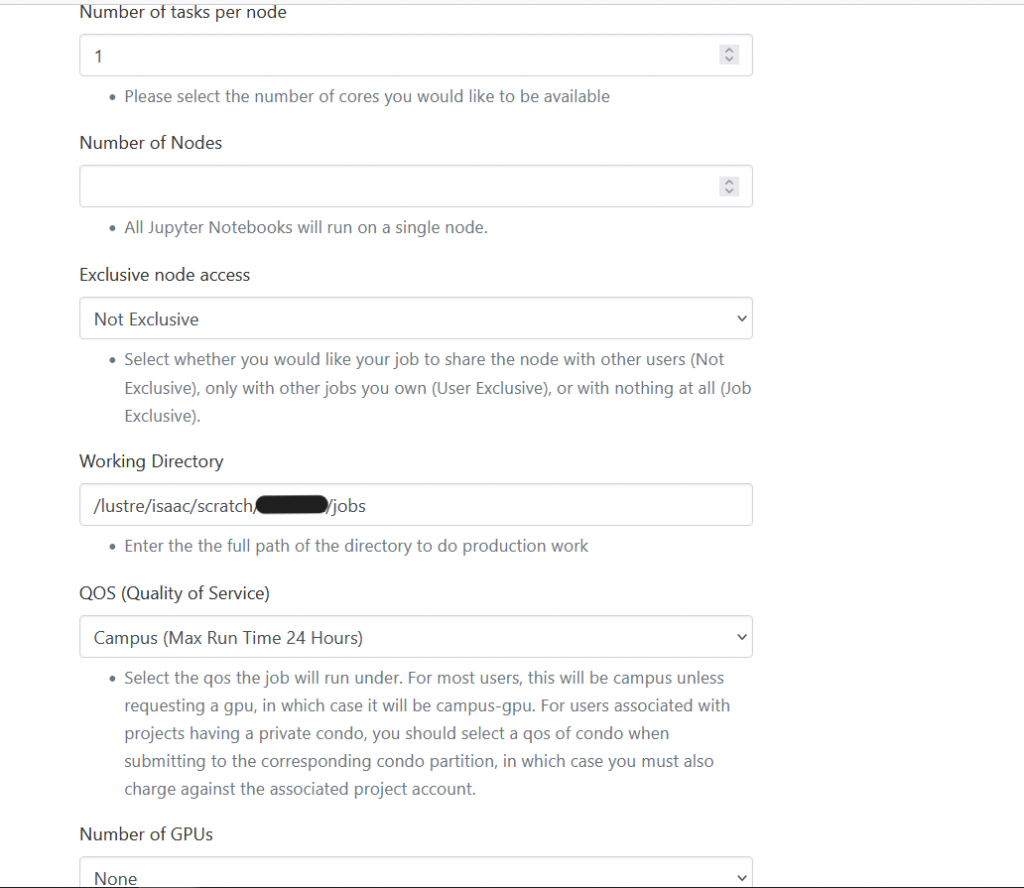
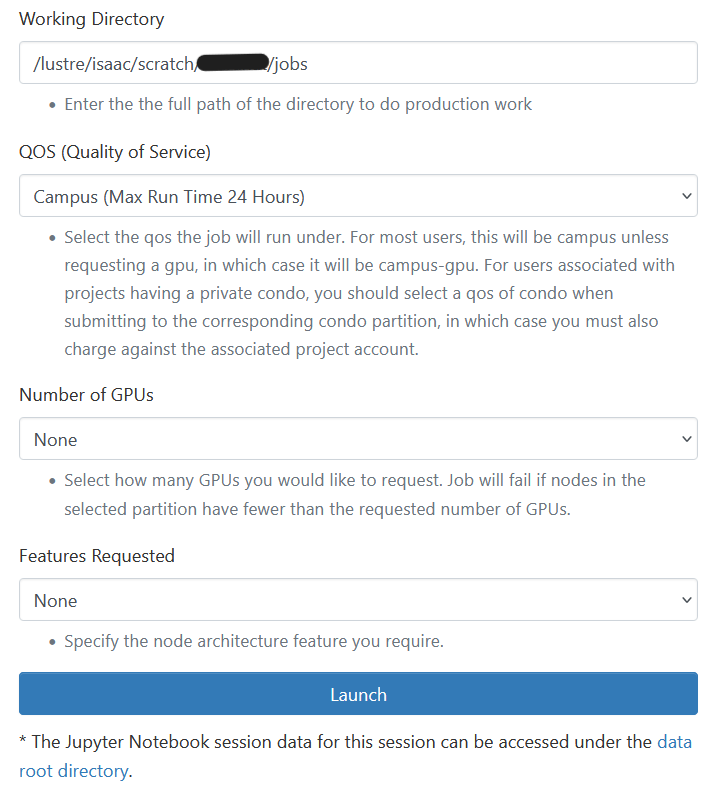
The below shows how to fill in the form with the information needed to start request allocating resources for the work for one core on one node with no GPU for one hour:
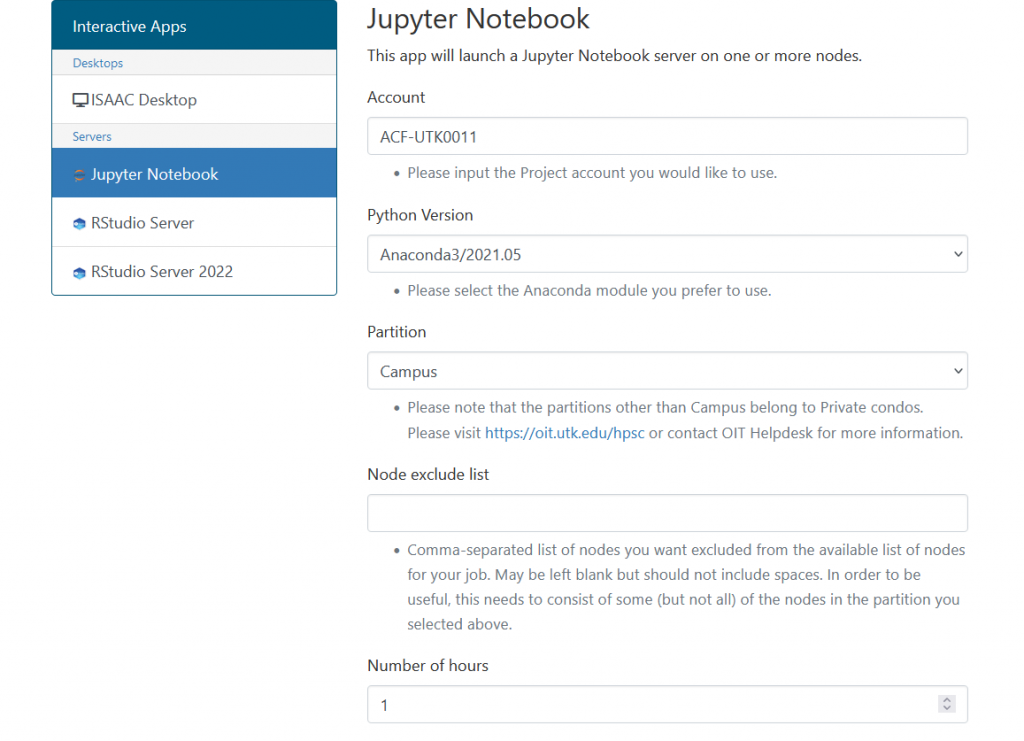
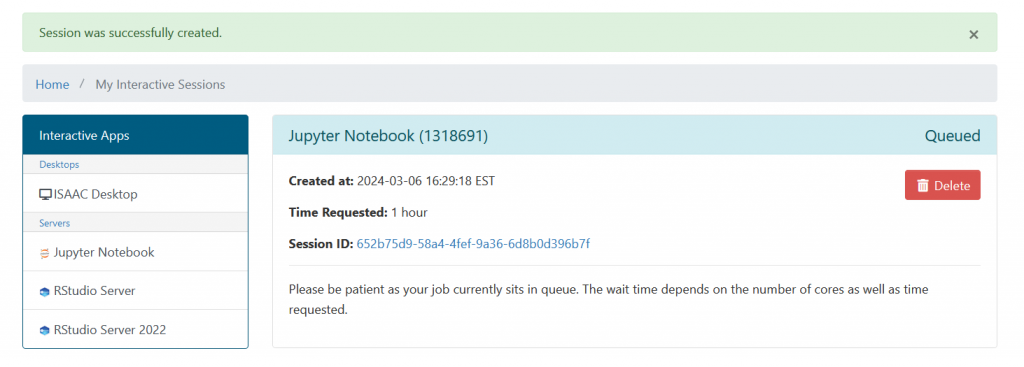
The session will be in Queue until the resources are free to use.
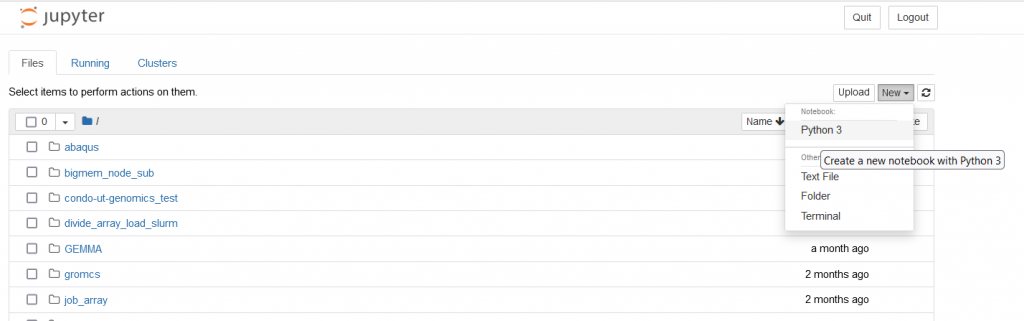
When the resources are allocated by SLURM and the Jupyter Notebook environment is ready and running, select “Connect to Jupyter”.
From “New” drop-down menu, select “Python 3”
As shown in the notebooks below, you can run Linux commands by adding an exclamation mark (!) before each command.
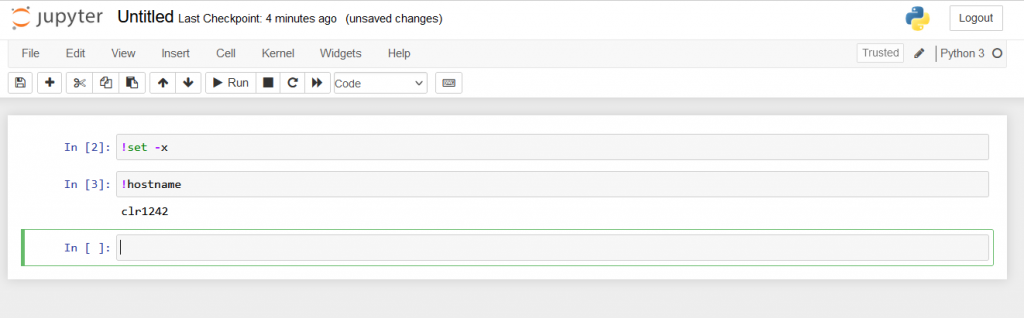
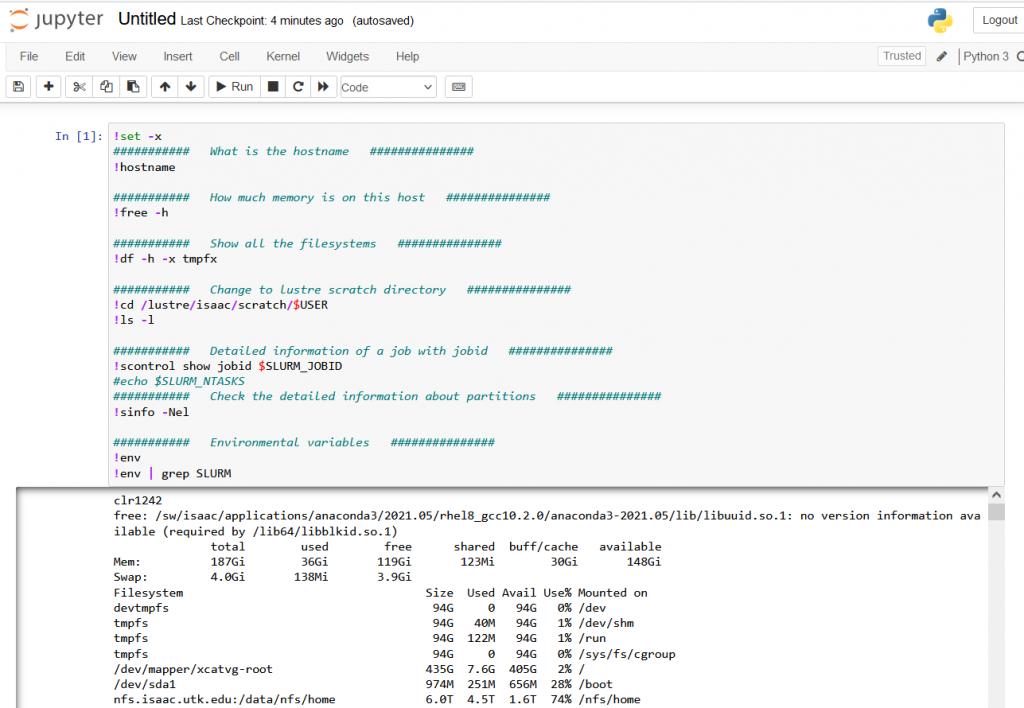
Example 2 – Jupyter Notebook Long GPU Job (long_gpu.sh)
For this example, we will look at the example job long_gpu.sh located in the example jobs directory at /lustre/isaac/examples/jobs.
Let’s go ahead and look at the sbatch directives for this script:
We need to use these same parameters in Open OnDemand to run this script. The figure below shows the form and the information needed to run this script:
After, wait for your job to run while it’s in the queue. You will know when you are ready to run the job when you see the following status. You will need to press the “Connect to Jupyter” button to access your job.
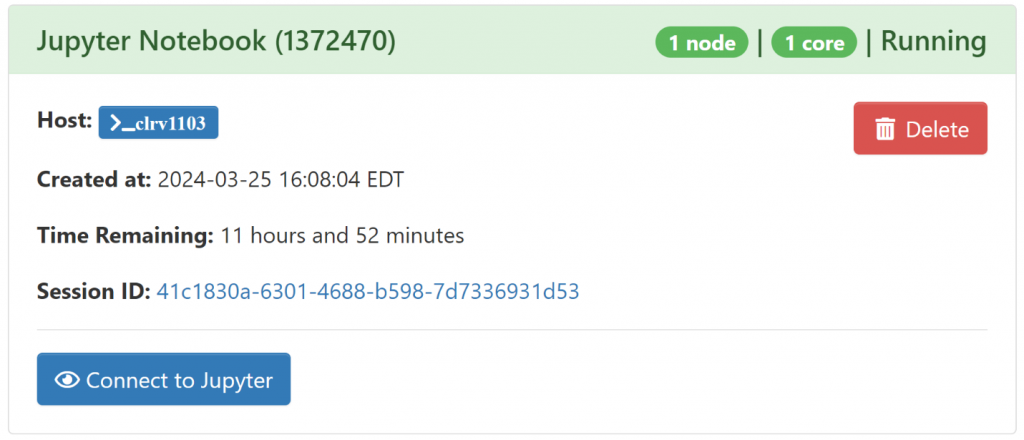
In your Jupyter notebooks, you will want to right click and select “New Notebook”.
This will then open a new notebook where you can run your script and commands. Again, do not forget the ‘!’ when running Linux commands or else it will treat the line as a line of Python. Paste the long_gpu.sh script into one cell, adding ‘!’ in front of each command, and you should be able to run it.

You should see the output right under the cell.

You can also run each command in its individual cell, so you can see the output for each command as it is called.
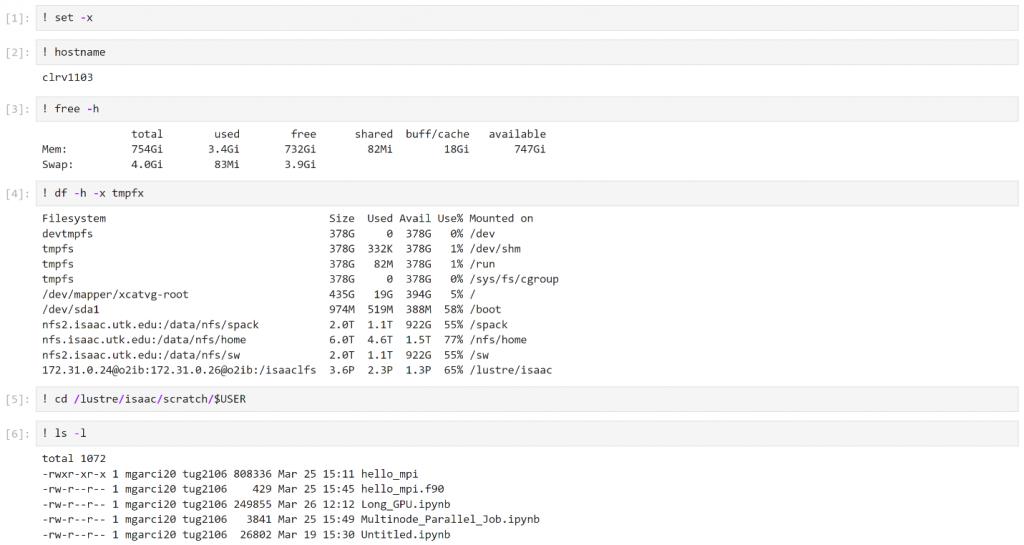
Example 3 – Jupyter Notebook AI CUDA job (ai_cuda_job.sh)
The “AI Tenn” partition and QOS was used in this example; make sure to use the appropriate account to use “AI Tenn”.
When the session is ready, you can use the Jupyter notebook for an interactive session and you can use a terminal to compile and use the installed software on the system.
Example 4 – Jupyter Notebook MATLAB job
In this example, we will reserve the “short” partition and QOS for 2 hours and set the number of tasks per node to 16.
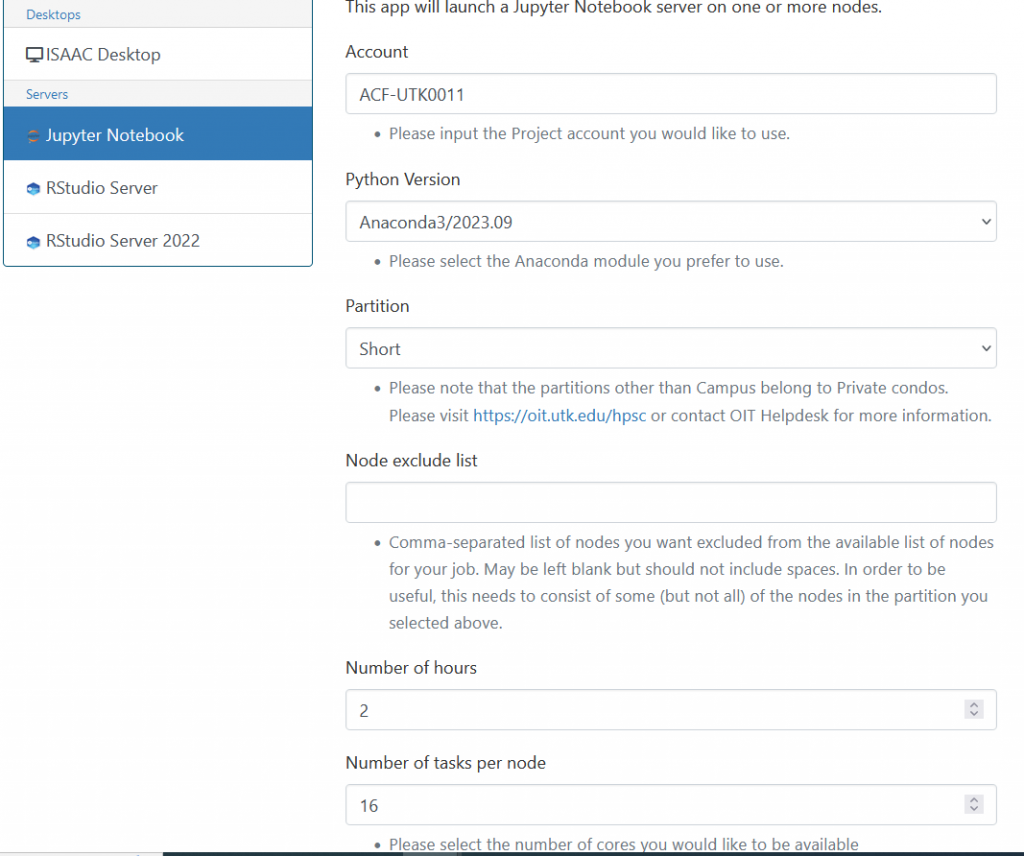
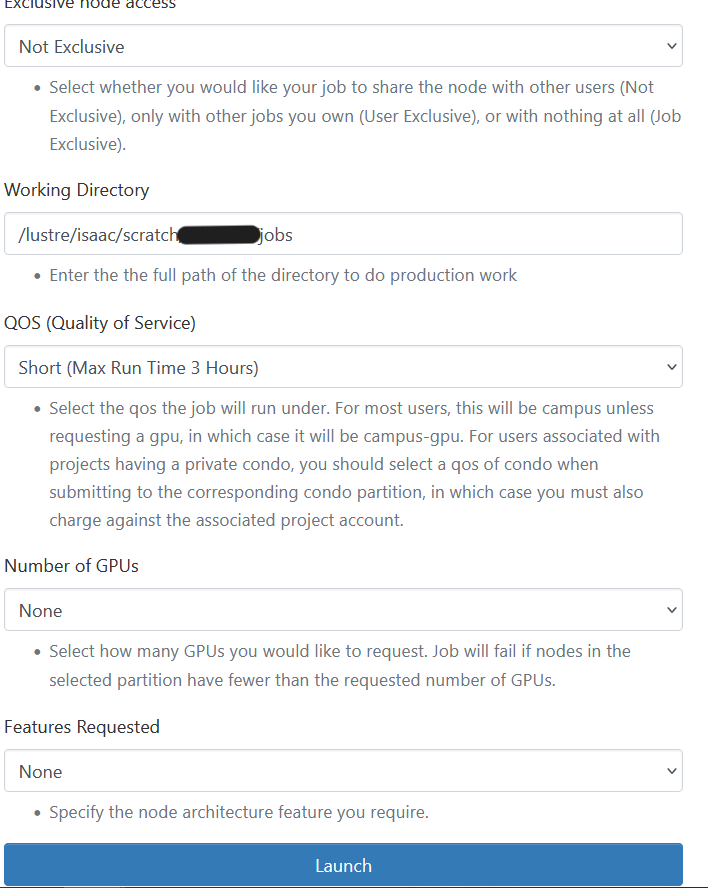
When the session is ready, you can use the terminal to load the matlab module and compile the example.

Common error example:
One common error that occurs during resource reservation is when the chosen QOS does not match the selected partition. For more information on QOS and partitions, please check the table shown at Running Jobs on ISAAC-NG.
The following shows the error message from OOD and includes SBATCH’s error message:
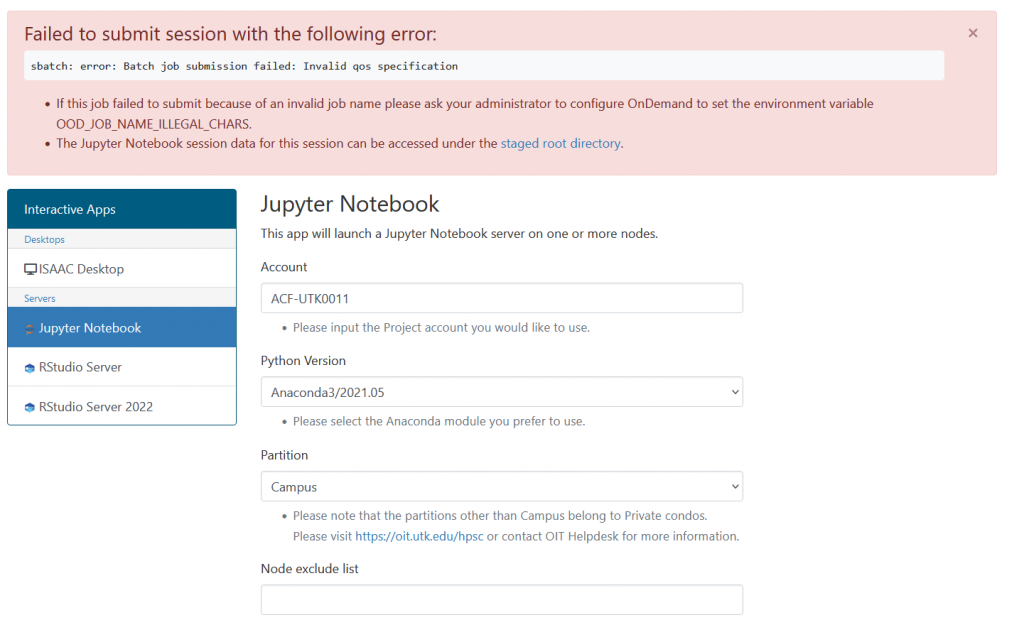
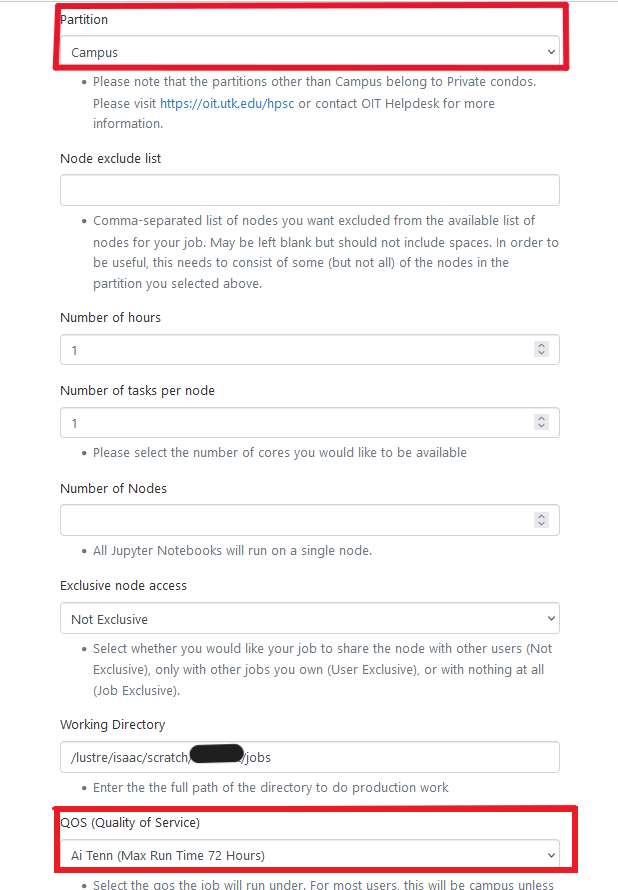
The error message indicates that the selected QOS is invalid. In this case, the partition is designated as ‘Campus,’ which should correspond to the ‘Campus’ QOS according to the table. However, the chosen QOS appears to be ‘AI Tenn.’
To resolve this issue, if the intended QOS is ‘AI Tenn,’ the partition should also be set to ‘AI Tenn,’ along with using the appropriate project account. Conversely, if the job requires only Campus resources, the QOS should be changed to ‘Campus’ instead of ‘AI Tenn.’